Konzepte
Objektmodell
Regal realisiert ein einheitliches Objektmodell in dem sich eine Vielzahl von Publikationstypen speichern lassen. Die Speicherschicht wird über Fedora Commons 3 realisiert.
Eine einzelne Publikation besteht i.d.R. aus mehreren Fedora Commons 3-Objekten, die in einer hierarchischen Beziehung zueinander stehen.
Datenstrom |
Pflicht |
Beschreibung |
|---|---|---|
DC |
Ja |
Von Fedora vorgeschrieben. Wird für die fedorainterne Suche verwendet |
RELS-EXT |
Ja |
Von Fedora vorgeschrieben. Wird für viele Sachen verwendet - (1) Hierarchien - (2) Steuerung der Sichtbarkeiten - (2) OAI-Providing |
data |
Nein |
Die eigentlichen Daten der Publikation. Oft ein PDF. |
metadata oder metadata2 |
Nein |
Bibliografische Metadaten. Metadata2 wurde mit dem Umstieg auf die Lobid-API v2 eingeführt. |
objectTimestamp |
Nein |
Eine Datei mit einem Zeitstempel. Der Zeitstempel wird bei bestimmten Aktionen gesetzt. |
seq |
Nein |
Eine Hilfsdatei mit einem JSON-Array. Das Array zeigt an, in welcher Reihenfolge Kindobjekte anzuzeigen sind. Dieses Hilfskonstrukt existiert, da in der RELS-EXT keine RDF-Listen abgelegt werden können. |
conf |
Nein |
Websites und Webschnitte speichern in einem conf-Datenstrom alle Parameter mit denen die zugehörige Webseite geharvested wurde. |
Die Metadaten werden als ASCII-Kodierte N-Triple abgelegt. Da alle Fedora-Daten als Dateien im Dateisystem abgelegt werden, ist diese Veriante besonders robust gegen Speicherfehler. N-Triple ist ein Format, dass sich Zeilenweise lesen lässt. ASCII ist die einfachste Form der Textkodierung.
Die Daten werden als “managed”-Datastream in den Objektspeicher der Fedora abgelegt. Eine Ausnahme bilden Webseiten. Die als WARC gespeicherten Inhalte werden “unmanaged” lediglich verlinkt. Im Fedora Objektspeicher wird nur eine Datei mit der ensprechenden Referenz abgelegt.
Namespaces und Identifier
Jede Regal-Installation arbeitet auf einem festgelegten Namespace. Wenn über die regal-api Objekte angelegt werden, finden sich diese immer in dem entsprechenden Namespace wieder. Hinter dem Namespace findet sich, abgetrennt mit einem Dopplepunkt eine hochlaufende Zahl, die i.d.R. über Fedora Commons 3 bezogen wird.
Der so zusammengesetzte Identifier kommt in allen Systemkomponenten zum Einsatz.
ID |
Komponente |
URL |
|---|---|---|
regal:1 |
drupal |
|
regal:1 |
regal-api |
|
regal:1 |
fedora |
|
regal:1 |
elasticsearch |
Deskriptive Metadaten
Regal unterstützt eine große Anzahl von Metadatenfeldern zur Beschreibung von bibliografischen Ressourcen. Jedes in Regal verspeicherte Objekt kann mit Hilfe von RDF-Metadaten beschrieben werden. Das System verspeichert grundsätzlich alle Metadaten, solange Sie im richtigen Format an die Schnittstelle gespielt werden.
Darüber hinaus können über bestimmte Angaben, bestimmte weitergehende Funktionen angesteuert werden. Dies betrifft u.a.:
Anzeige und Darstellung
Metadatenkonvertierungen
OAI-Providing
Suche
Alle bekannten Metadateneinträge werden in der Komponente Etikett verwaltet. In Etikett kann konfiguriert werden, welche URIs aus den RDF-Daten in das JSON-LD-Format von regal-api überführt werden. Außerdem kann die Reihenfolge der Darstellung, und das Label zur Anzeige gesetzt werden.
Label |
Pictogram |
Name (json) |
URI |
Type |
Container |
Comment |
|---|---|---|---|---|---|---|
Titel |
keine Angabe |
title |
String |
keine Angabe |
keine Angabe |
Etikett-Eintrag als Json.
"title":{ "@id"="http://purl.org/dc/terms/title", "label"="Titel" }
Die etikett Datenbank wird beim Neustart jeder regal-api-Instanz eingelesen. Außerdem wird die HTTP-Schnittstelle von Etikett immer wieder angesprochen um zur Anzeige geeignete Labels in das System zu holen und anstatt der rohen URIs einzublenden. Das regal-api-Modul läuft dabei auch ohne den Etikett-Services, allerdings nur mit eingeschränkter Funktionalität; beispielsweise fallen Anzeigen von verlinkten Ressourcen (und das ist in Regal fast alles) weniger schön aus.
Wie kommen bibliografische Metadaten ins System?
In Regal können bibliografische Metadaten aus dem hbz-Verbundkatalog an Ressourcen “angelinkt” werden. Dies erfolgt über Angabe der ID des entsprechenden Titelsatzes (z.b. HT017766754). Mit Hilfe dieser ID kann Regal einen Titelimport durchführen. Dabei wird auf die Schnittstellen der Lobid-API zugegriffen.
Regal bietet außerdem die Möglichkeit, Metadaten über Erfassungsmasken zu erzeugen und zu speichern. Dies erfolgt mit Hilfe des Moduls Zettel. Zettel ist ein Webservice, der verschiedene HTML-Formulare bereitstellt. Die Formulare können RDF-Metadaten einlesen und ausgeben. Zettel-Formulare werden über Javascript mit Hilfe eines IFrame in die eigentliche Anwendung angebunden. Über Zettel werden Konzepte aus dem Bereich Linked Data umgesetzt. So können Feldinhalte über entsprechende Eingabeelemente in Drittsystemen recherchiert und verlinkt werden. Die Darstellung von Links erfolgt in Zettel mit Hilfe von Etikett. Umfangreichere Notationssysteme wie Agrovoc oder DDC werden über einen eigenen Index aus dem Modul skos-lookup eingebunden. Zettel unterstützt zur Zeit folgende Linked-Data-Quellen:
Anzeige und Darstellung
Über die Schnittstellen der regal-api können unterschiedliche Darstellungen einer Publikation bezogen werden. Über Content Negotiation können Darstellungen per HTTP-Header angefragt werden. Um unterschiedliche Darstellungen im Browser anzeigen zu lassen, kann außerden, über das Setzen von entsprechenden Endungen, auf unterschiedliche Representationen eine Resource zugegriffen werden.
Auswahl von Pfaden zu unterschiedlichen Representationen einer Ressource.
/resource/regal:1 /resource/regal:1.json /resource/regal:1.rdf /resource/regal:1.epicur /resource/regal:1.mets
In der HTML-Darstellung greift regal-api auf den Hilfsdienst Thumby zu um darüber Thumbnail-Darstellungen von PDFs oder Bilder zu kreieren. Bei großen Bildern wird außerdem der Deepzoomer angelinkt, der eine Darstellung von hochauflösenden Bildern über das Tool OpenSeadragon erlaubt. Video- und Audio-Dateien werden über die entsprechenden HTML5 Elemente gerendert.
Der hbz-Verbundkatalog
Metadaten, die über den Verbundkatalog importiert wurden, können über einen Cronjob regelmäßig aktualisiert werden. Außerdem können diese Daten über OAI-PMH an den Verbundkatalog zurückgeliefert werden, so dass dieser, Links auf die Volltexte erhält.
Metadatenkonvertierung
Für die Metadatenkonvertierung gibt es kein festes Vorgehensmodell oder Werkzeug. I.d.R. gibt es für jede Representation eine oder eine Reihe von Javaklassen, die für eine On-the-fly-Konvertierung sorgen. Die HTML-Darstellung basiert grundlegend auf denselben Daten, die auch im Elasticsearch-Index liegen und ist im wesentlichen eine JSON-LD-Darstellung, die mit Hilfe der in Etikett hinterlegten Konfiguration aus den bibliografischen Metadaten gewonnen wurde.
OAI-Providing
Öffentlich zugängliche Publikationen sind auch über die OAI-Schnittstelle verfügbar. Dabei wird jede Publikation einer Reihe von OAI-Sets zugeordnet und in unterschiedlichen Formaten angeboten.
Set |
Kriterium |
|---|---|
ddc:* |
Wenn ein dc:subject mit dem String “http://dewey.info/class/” beginnt, wird ein Set mit der entsprechenden DDC-Nummer gebildet und die Publikation wird zugeordnet |
contentType |
Der “contentType” weist darauf hin, in welcher Weise die Publikation in Regal. Abgelegt ist. |
open_access |
All Publikationen, die als Sichtbarkeit “public” haben |
urn-set-1 |
Publikationen mit einer URN, die mit urn:nbn:de:hbz:929:01 beginnt |
urn-set-2 |
Publikationen mit einer URN, die mit urn:nbn:de:hbz:929:02 beginnt |
epicur |
Publikationen, die in einem URN-Set sind |
aleph |
Publikationen , die mit einer Aleph-Id verknüpft sind |
edoweb01 |
spezielles, pro reg al-api-Instanz konfigurierbares Set für alle Publikationen, die im aleph-Set sind |
ellinet01 |
spezielles, pro reg al-api-Instanz konfigurierbares Set für alle Publikationen, die im aleph-Set sind |
Format |
Kriterium |
|---|---|
oai_dc |
Alle öffentlich sichtbaren Objekte, die als bestimmte ContentTypes angelegt wurden. |
epicur |
Alle Objekte, die eine URN haben |
aleph |
Alle Objekte, die einen persistenten Identifier haben |
mets |
Wie oai_dc |
rdf |
Wie oai_dc |
wgl |
Format für LeibnizOpen. Alle Objekte die über das Feld “collectionOne” einer Institution zugeordnet wurden und über den ContentType “article” eingeliefert wurden. |
Suche
Der Elasticsearch-Index wird mit Hilfe einer JSON-LD Konvertierung befüllt. Die Konvertierung basiert im wesentlichen auf den bibliografischen Metadaten der einzelnen Ressourcen und wir mit Hilfe der in Etikett hinterlegten Konfiguration erzeugt.
Zugriffsberechtigungen und Sichtbarkeiten
Regal setzt ein rollenbasiertes Konzept zur Steuerung von Zugriffsberechtigungen um. Eine besondere Bedeutung kommt dem lesenden Zugriff auf Ressourcen zu. Einzelne Ressourcen können in ihrer Sichtbarkeit so eingeschränkt werden, dass nur mit den Rechten einer bestimmten Rolle lesend zugegriffen werden kann. Dabei kann der Zugriff auf Metadaten und Daten separat gesteuert werden.
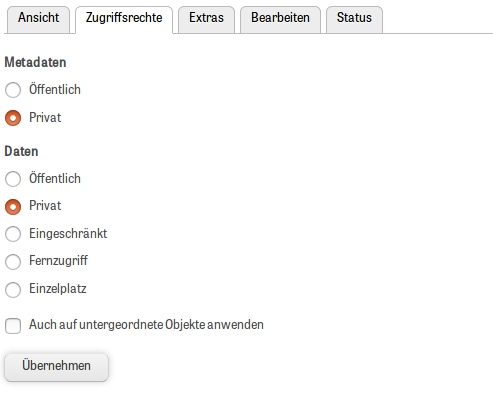
Screenshot zur Verdeutlichung von Sichtbarkeiten in Regal
Die Konfiguration hat Auswirkungen auf die Sichtbarkeit einer Publikation in den unterschiedlichen Systemteilen. Die folgende Tabelle veranschaulicht den derzeitigen Stand der Implementierung.
Sichtbarkeiten, Operationen, Rollen
Rolle |
Art der Aktion |
|---|---|
ADMIN |
Darf alle Aktionen durchführen. Auch Bulk-Aktionen und “Purges” |
EDITOR |
Darf Objekte anlegen, löschen, Sichtbarkeiten ändern, etc. |
Sichtbarkeit |
Rolle |
|---|---|
public |
GUEST, READER, SUBSCRIBER, REMOTE, ADMIN,EDITOR |
private |
ADMIN, EDITOR |
Sichtbarkeit |
Rolle |
|---|---|
public |
GUEST, READER, SUBSCRIBER, REMOTE, ADMIN, EDITOR |
restricted |
READER, SUBSCRIBER, REMOTE, ADMIN, EDITOR |
remote |
READER, SUBSCRIBER, REMOTE, ADMIN, EDITOR |
single |
SUBSCRIBER, ADMIN, EDITOR |
private |
ADMIN,EDITOR |
Benutzerverwaltung
Die Benutzerverwaltung von Regal findet innerhalb von Drupal statt. Zwar können auch in der regal-api Benutzer angelegt werden, jedoch ist die Implementierung in diesem Bereich erst rudimentär.
Drupal
Benutzer in Drupal können über das Modul regal-drupal unterschiedlichen Rollen zugewiesen werden. Die Authorisierung erfolgt passwortbasiert. Alle Drupal-Benutzer greifen über einen vorkonfigurierten Accessor auf die regal-api zu. Alle Zugriffe erfolgen verschlüsselt unter Angabe eines Passwortes. Die Rolle mit deren Berechtigungen zugegriffen wird, wird dabei in regal-drupal gesetzt. Die Drupal-BenutzerId wird als Metadatum in Form eines proprietären HTTP-Headers mit an regal-api geliefert.
Regal-Api
Auch in regal-api können Api-Benutzer angelegt werden. Zur Benutzerverwaltung wird eine MySQL-Datenbank eingesetzt, in der die Passworte der Nutzer abgelegt sind.
Ansichten
Um Daten, die in regal-api abgelegt wurden zur
Anzeige zu bringen sind i.d.R. mehrere Schritte nötig. Die genaue
Vorgehensweise ist davon abhängig, wo die Daten abgelegt werden (in
welchem Fedora Datenstrom). Grundsätzlich basiert die HTML-Darstellung
auf den Daten, die unter dem Format .json2 einer Ressource abrufbar
sind und einen Eintrag in context.json haben.
Daten zur Ansicht bringen
Eintrag des zugehörigen RDF-Properties in die entsprechende Etikett-Instanz, bzw. in die
/conf/labels.json. Der Eintrag muss einen Namen, ein Label und einen Datentyp haben. regal-api neu starten, bzw mitPOST /context.jsondas neu Laden der Contexteinträge erzwingen.Dies müsste reichen, um eine Standardanzeige in der HTML-Ausgabe zu erreichen
Wenn die Daten nicht erscheinen, sollte man überprüfen, ob sie unter dem Format
.json2erscheinen. Wenn nicht, stellt sich die Frage, wo die Daten abgelegt werden. Komplett werden nur die Daten aus dem Fedora Datenstrom /metadata2 prozessiert. Befindet sich das Datum in z.B. im /RELS-EXT Datenstrom so muss es zunächst manuell unterhelper.JsonMapper#getLd2()in das JSON-Objekt eingefügt werden.Einige Felder werden auch ausgeblendet. Dies geschieht in regal-api unter
/public/stylesheets/main.cssund in Drupal innerhalb der entsprechenden themes.Um spezielle Anzeigen zu realisieren muss schließlich im HTML-Template angefasst werden, unter
/app/views/tags/resourceView.scala.html.
Insgesamt läuft es also so: Alles was in Etikett konfiguriert ist, wird auch ins JSON und damit ins HTML und in den Suchindex übernommen. Dinge, die im HTML nicht benötigt werden, werden über CSS wieder ausgeblendet.